Jul 22, 2007
I have seen (and replaced) enough home-grown content management systems to know that they are not as easy to build as you would think. As a software architect, I understand the temptation. You just want something simple and you don't want to put up with all the compromises, limitations, and cost that a CMS framework comes with. After all, its just a matter of writing some data to the database and then presenting that same data elsewhere. We have all designed dozens of systems that do that! And look! You can even download a free WYSIWYG editor to make your homebrew CMS usable?
But before you go ahead and build the one billion and first CMS, here are some things that typically burn generalist architects when they try to design their first CMS.
Versioning. Frequently, the single requirement that kills a custom CMS is versioning - especially if it is added in after the initial design. Versioning is hard. It is hard because it makes your data model more complicated. It is hard because it is a concept that most generalist architects haven't implemented before. There are all of these interesting nuances like how often to create a new version (with every save, or every time it is published?) or the need to link to a specific version of an asset or just the latest version. If you want to get an idea just how hard versioning is, look at Plone. They have been trying to build versioning into the core for years (see Plone Versioning Mailing list). Finally, in the upcoming 3.0 release, Plone will have versioning.
Localization. Localization isn't just about Unicode. It is a whole other dimension of of your content repository. While adding versioning doubles the complexity of a data model, versioning combined with localization makes chaos if you are not careful. Does each translation have multiple versions? Or does each version have multiple translations? What language do you fall back to if you don't have a translation of an asset in the requested language? What is the relationship between the URLs of the translated sites? How do your presentation templates handle it when text runs right to left or up and down? Do all of the attributes of an asset need to be translated or can some things (like images) be shared?
Preview. Authors love preview. They like to see what their content is going to look like on the rendered page before everyone else sees it. The higher the fidelity the preview has, the better. Sometimes, just looking at the rendered detail page is enough. Other times, users want to be able to navigate through a full preview environment to see how the asset appears as related links on other pages and even search results. To deliver serviceable preview, you are going to need different presentation environments and versioning. Otherwise, every time the user clicks save on a published asset, the live site will update.
Deployment and dependency management. Content, especially web content is interrelated. Pages reference images and have links to other pages. If you are going to deploy a piece of content to the presentation tier, what will you do if the related assets are not ready for publishing and/or not deployed? Would you even know?
Usability. While the content management market cannot claim to have mastered usability, they have probably spent more time refining their user interfaces than you can afford to. Usability is probably the most common reason why companies abandon their home grown CMS.
Access control. Most software systems are designed to manage access control by function, not by data. Most (although definitely not all) content management systems have figured out a manageable system for controlling permissions around data.
If you are never going to have any of these requirements, go ahead. Write your own CMS. Just be prepared to throw it away when you grow out of it. Better yet, use frameworks and components that already deliver these key services. For example, a JCR compliant content repository will support most of these core repository services (check-in, check-out, versioning, workspaces). A workflow engine will help you keep ever changing workflow definitions out of your code and in a more manageable definition format. Also, look at lots of products out there and try to understand the reasons behind their design. What you see now in these products probably reflects years of evolution driven by requirements that you face now or will someday in the future.
Jul 18, 2007
Packt Publishing is holding their second annual Open Source Content Management System competition. Most of the project mailing lists that I subscribe to are announcing the competition and encouraging subscribers to vote. You can vote too.
While this competition will not tell you what CMS is right for you, it does give visibility into the volume (in people and decibels) of the community and the general, mass market appeal of the product. The 2006 winner was Joomla! followed by Drupal and Plone. This year, there will be multiple categories to try to spread the wealth (larger prize purse this year). The categories are:
-
Overall Winner
-
Most Promising Open Source CMS
-
Best Open Source PHP CMS
-
Best Other Open Source CMS
-
Best Social Networking CMS
What I would like to see is more categories focused on intended use. Social Networking CMS is an example, I think there could be categories for "Web Publishing System" (for things like online periodicals), "Website Management Tool" (for managing a corporate brochure site), and "Web Application Development Framework" (for building interactive, content centric applications).
Scott Abel is one of the judges this year. If you have ever seen him do one of the "Idol" competitions at Gilbane or another conference, you know you can expect some funny commentary.
Jul 16, 2007
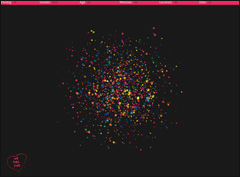
We Feel Fine "is an exploration of human emotion on a global scale." The site scans the blogosphere for phrases like "I am feeling" or "I feel" and presents these results in this really cool user interface. The site has 6 Movements (Madness, Murmers, Montage, Mobs, Metrics and Mounds) that show different visualizations of these data. For example, in the Madness movement, "Each particle represents a single feeling, posted by a single individual. The color of each particle corresponds to the tone of the feeling inside – happy positive feelings are bright yellow, sad negative feelings are dark blue, angry feelings are bright red, calm feelings are pale green, and so on. The size of each particle represents the length of the sentence contained within. Circular particles are sentences. Rectangular particles contain pictures."
This is an interesting use of feeds and a powerful way to visualize lots of data. I could see this as an effective tool for companies that have successfully adopted blogging within the enterprise and are now struggling for a way to take a pulse on what their employees are saying and feeling.
Jul 05, 2007
The official stable version of OpenCms V7 is now available pretty much right when the project team said it would be. Key enhancements (in my opinion) are WebDAV support, a content relationship engine for dependency management, and point in time preview (where you can go select a date in time to see what the site looked (or will look) like. An undelete feature for deleted content is also very welcome. The OpenCms.org website has had a face lift too.
In other news, the Apache Lenya project, which has been working for three years to release version 1.4, is probably going to call this version "2.0." There was some debate on the mailing list about the ethics of this re-designation ("is this being done just for marketing reasons?"). However, since much of the code has been re-written for this release and it has been three years in the making, I would say that it deserves a major release number. It is actually quite interesting to compare the angst in version number honesty in open source software to commercial software where it is pretty much all marketing.
Jun 25, 2007
Last week I was at the Enterprise 2.0 conference in Boston for a panel on Enterprise Search (if you missed it, there were some prolific bloggers there. In particular , Michael Sampson, who may have typed every word he heard, and my former colleague John Eckman. There were also video cameras at many of the sessions and I imagine that they will be posted here). For our session, we planned a fairly interactive agenda with a bunch of screencasts and then a dialog among the panelists and the audience. About 30 minutes into the 60 minute session, we realized that we could have had a whole track dedicated to this topic.
Like it or not, search is turning into the interface of web 2.0. Search is the glue that ties together all those fun to use collaboration tools like wikis and blogs. The simple search box brilliantly hides all the PhD-class, post-doctorate algorithms and complexity that makes sense of a chaotic Web 2.0 world.
But search is also a crutch and an enabler for not taking the time to organize and manage content. People who use GMail or Google Desktop don't use folders anymore. They keep their content in one large vat of informational soup. Usually searching turns up things that they forgot they had or wouldn't have thought to organize in that way. People find it much better than the deeply nested folder structures that are forgotten soon after creation. If you drink the search Kool Aid, "unmanaged" content starts to look less like a smothering and chaotic avalanche of virtual paper, and more like this protoplasm of information that nourishes business processes throughout the organization.
Back in reality, many companies are finding less success with their enterprise search engines. Business users wonder why Intranet search can't be as good as Google on the web. The standard response is that Intranet search is harder than Internet search. I say both are really hard but in different ways. While Internet search is dealing with unimaginable volumes of data and traffic and continuous attempts to manipulate the results for personal gain, Intranet search suffers from stagnation and lame content. That and the fact that an Intranet search engine has to negotiate more complex access control rules than an Internet search engine does. Still, I think that if the Intranet had better content, Intranet search would be better.
What do I mean by better content? We can start by more linking. Internet search engines benefit from blogs and social bookmarking which create a meritocracy of content. Click through rates also help a search engine learn what is good. Writing good descriptions of content can help drive click through rates and prevent users from having to backtrack after being misled (the search engine learns from that behavior as well). That raises another (and maybe the most important) question: why would employees want to create good content on the Intranet? I know why people like myself out there in the blogosphere try to write good content. In addition to all the millions I am making on Google AdSense (totally not by the way. Would it kill you to click on a link?), I get a lot of professional benefit from blogging. I can put out ideas and have very knowledgeable people respond and help me refine them. I connect with people who can use my expertise or have similar interests and challenges. My blog is also a great archive to help me remember things that I have seen and what I thought about them.
Writing on an internal corporate blog was far less rewarding. Hardly anyone read my internal blog even after continuous attempts to promote it (as in when people sent company-all emails asking a question I would point them to a post that I wrote on the topic). And this was at a company that was supposed to be ahead of the curve. Using blogs and wikis as the communication tool on project teams was more effective (because I was managing the team and I wrote the performance reviews). I wrote a post about how we used Trac. It was very effective but what was missing from the equation was some way for people to categorize and promote really good content so they turned up in search results. We could have installed a social bookmarking software like Scuttle but, if you are like me, you would want to use something like del.icio.us or digg for external links and the internal system for internal links. That way, when you leave, you get to keep your bookmarks to pages that you still have access to. Here is an interesting thought... now that we have reached a point where people think of their computers (or PDAs) as an extension of their brain, is it reasonable to make them leave this data behind to be formatted when they leave?
I heard several times at the conference that knowledge management is 90% people and 10% technology but what I didn't see was how to get people to step up and deliver their 90%. Most of the ideas that I heard were around making it easier. I think that the secret to Enterprise 2.0 is how to make collaboration and knowledge sharing more personally rewarding. That is where I think we can learn the most from Web 2.0 (more so than with the mechanics of blogs, wikis, and tagging). People out on the web want to publish and put in extra effort to get their contributions noticed. Maybe companies should create their own internal information economies that reward employees for creating content that other people want to read. Maybe reward for hits or positive votes or links toward. Maybe companies should come up with ways to reduce the risk of an employee sharing his private knowledge base? If the company has a social bookmarking system, why not let users export their links into a format that can be imported into del.icio.us when they leave? Doing so would encourage people to share external links as well.
If your employees are motivated, they will overcome obstacles like poor usability. They will find a way to address issues like ownership. They will stop looking for excuses not to participate. They will tap into their entrepreneurial creativity to improve the flow of information in your organization.
Jun 21, 2007
On Monday I presented at the Web Content 2007 conference in Chicago. Congratulations to the guys (and gals) from DUO Consulting for putting on a great conference. From talking to folks it looks like this is going to turn into an annual event so mark your calendars for Web Content 2008! I was only there for the day but the sessions that I attended were really good. CMS Wire had two bloggers (Marisa Peacock and Aaron Bailey) covering the event so you can read their posts there. In the one day I saw Ann Rockley's keynote, Bryant Shea's talk on user generated content, David Esrati's BlogZilla presentation, Stewart Mader's talk on wikis, and Ståle Eikeri's discussion of Web 2.0. As an aside, I saw Stewart 2 days later at the Enterprise 2.0 conference in Boston. I guess I am not the only one with a crazy travel schedule.
During lunch, Howard Tullman was able to overcome the crunching of potato chips to keep the audience engaged in a presentation on driving organizational change. Based on questions from the audience in all of the sessions, it seemed that many of the attendees were trying to figure out a way to get their organizations to adopt these ideas about using content more effectively. I hope they got the ammunition that they needed to start initiating better content management practices when they returned to their offices on Wednesday.
Jun 19, 2007
We all dream about a unified view of content but maybe this goes a little too far?
Jun 19, 2007
Dave Schoorl just announced on the OpenCms mailing list his new Eclipse plugin for OpenCms module development. This plugin provides direct synchronization with OpenCms's virtual file system. Lack of WebDAV support for the VFS has made developing code for OpenCms a little awkward because you develop locally and then need to figure out some way to push it to the server. Dave's plugin handles the synchronization behind the scenes so you don't have to worry about it. OpenCms Version 7 (currently in Beta) includes WebDAV support but there is still great value of having an Eclipse plugin because it sets the foundation for lots of other developer conveniences. This is the strategy that many commercial CMS products are taking: rather than try to build your own stand alone IDE, sit on top of a solid foundation that is familiar to most developers.
Jun 15, 2007
Graham Oakes has a great article about CMS consolidation in the Financial Times. Companies could have saved a lot of money had they read Graham's article 5 years ago when centralized ECM was on everyone's list of initiatives. One of my favorite points from the article:
Is this really a process rationalisation project? Of course, there is often no real reason for the different processes. They just grew that way. In this case, rationalising processes makes a lot of sense.
However, many organisations try to use technical consolidation to force business process rationalisation. This is a risky strategy. Change management is hard enough at the best of times. When management attention is focused on technology, it is hard to engage the right players and easy to overlook key factors. If process rationalisation is the real issue, it is best to face it head on.
Sometimes technology projects are just excuses to address more systemic issues. That or getting some sexy new technology is used as a bribe for getting people to change the way they do things.
Graham also makes the point that consolidation frequently has the side effect of making the whole organization move at the pace of the smallest business group. I would go further and say that having every division on the same CMS slows the pace of innovation and enhancement to a pace that is slower than the slowest business group. A single system that serves everyone has so many dependencies (both functional and political) that it is nearly impossible to get anything done.
I think the market has largely accepted that having one CMS to manage everything is a pipe dream. I think that Graham makes the points especially eloquently. So if you need to talk someone out of a major consolidation strategy, please use Graham's arguments. Then try to achieve the same goals with targeted tools, better integration and improved processes.
Hat tip to the CM Pros Benelux for pointing the article out.
Jun 13, 2007
Graffito is an Apache project to build a set of content management components that can be used within portals and other applications. Here is what I wrote about Graffito back in February 2005. Graffito has been in the Apache Incubator for quite some time and has not been able to graduate to a top level project. I just read on Christophe Lombart's blog (Content Type - love the name BTW), that Graffito is going to be folded into the JackRabbit project (that itself graduated from the Incubator in March of 2006). JackRabbit is the reference implementation for the JCR and was critical in getting JSR 170 through the Java Community Process. It promises to do the same for JSR 283 which will improve the JCR spec. JackRabbit also absorbed many of the developers from the Jakarta Slide project (an open source implementation of WebDAV). Most of the developers on Graffito came from the Apache Portals projects and I guess Graffito could have been absorbed by portals as well. I agree with Christophe that JackRabbit makes a lot of sense because the two projects are aligned around the goal of creating building blocks for content management systems. Graffito has also done a considerable amount of work building JCR support into the project.