Mar 12, 2013
Replatforming your website to a new web content management system is an expensive proposition. In fact, a CMS migration can be so expensive and risky, that I advised many of my CMS selection clients against doing it. That is not to say that there are not perfectly legitimate reasons to replace a CMS. The wrong CMS can hold you back and prevent you from seizing valuable opportunities. But one sure fire way to spot a foolish CMS replacement project is when it is justified by a return on investment (ROI) calculation that relies on future labor cost savings to offset the price of an expensive CMS.
The truth is, if you make a big CMS investment, you will probably spend more time managing your content and optimizing the experience for your visitors. Why? Because advanced (expensive) web content management systems allow you to do more sophisticated things like personalization, multivariate testing, and advanced analytics. If your CMS has these features, you better actively manage them because neglecting advanced engagement functionality is worse than not having it in the first place. Buying an expensive CMS to avoid the human effort of managing a website is about as silly as buying an expensive car because you want to spend less time driving.
If you must show an ROI projection to justify the cost of a new web content management system, focus on the top line. Talk about the value (or potential value) of your content. Talk about the opportunity to reach new markets or connect with potential customers in new ways. And make sure to set aside plenty of budget for people to operate and get the most out of that CMS. To learn about all that goes into effective an marketing operations program, see me present at the Now What Conference next month.
If you want to treat your website like a project where you "do the website" and then forget it about it for a few years, I would seriously consider ripping out your CMS entirely and build a nice static brochure website that you can cheaply host. If you just need to make occasional updates, there are lots of cheap and free web content management products available. Many of these products can take you pretty far as you increase the intensity of your digital marketing program. But if you want to go high end, your initiative will fail unless you build a competent marketing operations program that gets the most out of the technology.
Mar 06, 2013
Here is a short and interesting video about the growing importance of citations to SEO. It is cool to see how Google's relevance algorithms are getting more sophisticated at understanding the meaning in content and identifying authority. Of course, the pessimist in me sees SEO bottom feeders interpreting this trend as justification for anti-social behavior like comment spam.
In the arms race between Google and the people who try to manipulate it, always side with Google. If you create great content and build an audience of influencers, you are Google's ally. Take short cuts and play tricks and you are one algorithm change away from total obscurity.
Feb 28, 2013
I have been loving the book Web Operations: Keeping the Data On Time

. It is indispensable reading for anyone responsible for hosting a web application or any important website. As the editors say, web operations is an emerging field with little in the way of training programs or officially sanctioned best practices. Nobody is classically trained. The best web ops people grew up in the field and learned from other greats and being faced with tough challenges.
One of the book's chapters is a reprint of an academic article called How Complex Systems Fail by Richard I. Cook. Interestingly, this article wasn't written about Web Ops at all. Richard Cook is an MD and he was writing about hospitals and healthcare. But the similarities with web ops are striking. It's a quick read and it's free. The points that were especially salient to me were:
-
"Complex systems contain changing mixtures of failures latent within them."
The more fault tolerance you add, the more unnoticeable little failures become. And even when you notice them, issues can be fleeting and too difficult and/or not important enough to fix. You just live with them. Even if you have a very simple set up, the cloud hosting service that you are running it on is incredibly complex — so complex that it can suffer from living organism diseases like auto-immune vulnerabilities. When adding yet another layer of complexity to make your system more resilient, sometimes you introduce more potential for failure that may reduce the health of the overall system. Our hosting infrastructure has lots of redundancy built into it. But sometimes I yearn for simpler times when I had one physical server that I just rebooted when things got ugly.
-
"All practitioner actions are gambles."
There are a few points in the article that deal with post accident analysis. As frantic as it feels to have a site outage, the author is talking about much higher stake failures (he's a doctor, remember). But his analysis is right on. Whenever we do anything, we are making a gamble — no matter how much we test. Sometimes the risk of the gamble is much less than the risk or opportunity cost of doing nothing. But you can't always tell. It is easy to get down on yourself or your team when a mistake is made or a failure occurs. But as the article says: "That practitioner actions are gambles appears clear after accidents; in general, post hoc analysis regards these gambles as poor ones. But the converse: that successful outcomes are also the result of gambles; is not widely appreciated." In other words, system improvement depends on gambles.
-
"People continuously create safety."
The point here is that you can't make anything totally idiot-proof. In the world of web ops, you can script things but you always need experienced people thinking about what they are doing and keeping an eye on things.
-
"Failure free operations require experience with failure."
This point really extends the previous point. The only way people get experience is by facing failure. In the early days of my career (amazingly, nearly 20 years ago), I worked in a tiny I.T. department serving a large and rapidly growing company. Our team was brilliant but inexperienced and we were constantly faced with new problems that we had to solve under pressure (my favorite was our "total network crash" that was actually the folding card table that held all of our servers collapsing). We all learned so much and everyone on the team went on to a successful career. But we wouldn't have learned anything if everything went smoothly. As a side note, I experienced more appreciation from the user community during those years than since. People saw that we were creative, dedicated, humble, and fearless. We didn't have that dysfunctional I.T. v.s. business dynamic. We were all in it together.
I know that the message I have been sending is that marketing I.T. is complex and messy and you just need to deal with it. To an extent, this is true. But it also means that whenever there is an opportunity to simplify something, you need to take it. I see every piece of unjustified complexity as a risk with unknown cost. It is easy to relate to the added up-front cost of adding a little flourish that makes an application more interesting. It takes experience to understand the long term cost of maintaining something that is more complicated than it needs to be. Even if that clever code is lucky enough not to break when something else changes, it will perpetually need to be circumnavigated by others who barely understand how it works. Before long, you have a culture of people who are afraid to touch things and cruft is inevitable.
If there is a way to do something in a more direct way, take that approach. When thinking of development costs, budget for the cost of maintaining that code. Prioritize refactoring and refinement over adding new features. Make is suck less. Most of all, don't let your complexity outgrow your capacity to manage. it.
Feb 15, 2013
I just ran across this great quote by Edsger W.Dijkstra:
It is practically impossible to teach good programming to students that have had a prior exposure to BASIC: as potential programmers they are mentally mutilated beyond hope of regeneration. (link)
The quote made me think of moving from Subverson to Git but there are lots of other great analogies. Going from document management to web content management can also be this way. For example, document management people tend to focus on files and metadata and it is hard for them to grasp that web content can be structured so there is no need to separate the two concepts. Breaking out of old models and thought habits is difficult, I find the only way to do it is to trust the new way and be willing to let go of your instincts. It is also helpful to have a zen-master style coach bringing attention to your implicit assumptions and supporting you when you stumble.
Feb 11, 2013
A couple of weeks ago I wrote a post describing how to make sure that your fail-over sites are running properly. At the time, I was sending the results via email. Since then, I improved the process by turning the logic into a ServerDensity plugin (I mentioned that we use ServerDensity here: Marketing I.T. in the Cloud). It was pretty easy to do. The only thing even remotely clever that I did was cache the results in a file so that I didn't have to check the sites every 5 minutes (which is the ServerDensity agent run frequency). Here is the code
Feb 04, 2013
When considering a translation proxy to localize a website, people often ask "if we change the content on the site, what will visitors see while the translators are working on the new translations?" Unless you are using machine translation as a backstop for untranslated content, your source language is going to show through. This is because a translation proxy doesn't cache full pages. Instead, they apply translations one fragment at a time. If it doesn't have a translation for a fragment, the translation proxy will register it as a new string to translate and send the original text through. This is a necessary trade-off to support dynamic websites. You can shorten the period of bleed-through by increasing your translation responsiveness and throughput, but to prevent bleed entirely you need apply one of the following techniques.
These two techniques are really just variations on the same theme of pointing the proxy at two versions of your site: one for content discovery and another one for production.
International Snapshot
The "international snapshot" approach is where you create a non-current snapshot of your production site for international audiences. Depending on your translation velocity, this could be anywhere from a day old to a month old or more. Content discovery and translation is still done on the live site. But when an external visitor browses the site, they are getting a proxy-translated view of the snapshot. There is no bleed-through from the snapshot site because by the time the snapshot is refreshed, all of the translation rules have already been published. Here is a picture
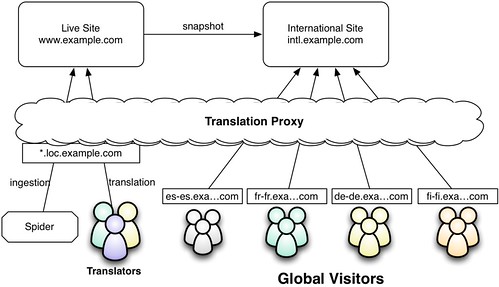
This is what we are doing for the new www.lionbridge.com website. We wrote some scripts to do a full snapshot of the site (code, database, and other files) to another virtual host on the same servers. If you are using a more sophisticated platform than Wordpress, you could probably set up another publishing target and just publish there when you want to update your snapshot.
Translate Staging
The "translate staging" option follows the same pattern as international snapshot. With translate staging, however, you do your content discovery and translation on the staging server (which has content which hasn't been published yet) so your translations are ready before you publish your content. Once your translation queue is down to zero, you can publish your source content to your live site and the translation rules will be waiting to be used.
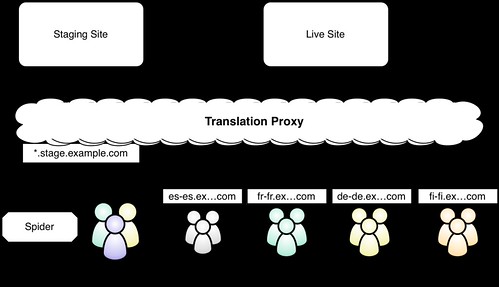
With "translate staging," you need to make sure:
-
Your staging site is publicly accessible. You will not be able to view the site through the proxy unless it is available on the public internet. For security reasons, you can limit access with a firewall and also add authentication to the staging site.
-
Your staging site only contains translation ready content. If you have are using your staging site for your editorial process, you might wind up discovering draft content that will never be published. Since this is obviously a waste of time and money, it's best to create a staging instance that only has content that is ready for publishing.
Here is a summary of the process
What to choose?
Which approach is right for you depends on your requirements. If, because of regulations or communications policy, you are required to publish new content to all languages simultaneously, you need to go with the translate staging option. If, like it is with us, you can allow your localized sites to lag behind the primary site, the international snapshot option is usually most attractive. And, of course, letting source content leak through may be acceptable if your site is less formal. The most important thing is that you have options.
Jan 11, 2013
As I mentioned in "Marketing I.T. in the Cloud," we maintain a hot-standby infrastructure on another hosting service. We automatically refresh this standby setup at a regular interval so that, if something really bad happened to our primary infrastructure, we could just re-point our domains and relatively recent versions of our sites would be back up.
Because this backup infrastructure is so critical, we monitor it just like our production infrastructure. One thing we have not been able to automate, however, is the check to make sure the front page is loading properly. The problem is that Wordpress forces a redirect to a primary host name. That is, if you try to hit the IP address of the backup server, it will redirect to the primary domain of the site (like http://www.globalmarketingops.com) which is still running on the primary servers. The fact that the redirect even happened told you Apache is running and Wordpress is able to read from the database. But you wouldn't know if the pages were broken. This is a little like driving around with a flat spare tire. You know you have it but you don't know it is useless until you try to use it.
Our work-around has been to manually edit our hosts file (which overrides the DNS) and browse the site on a regular basis. But that is a drag. I couldn't find a ping service that allowed me to override the public DNS with temporary mappings. So I came up with something much simpler.
I edited the /etc/hosts file of the backup server to map the supported domains to itself (localhost). With that setting in place, we can run a script on the backup server that loads the home page of each of the sites and verifies that each homepage contains certain text. The script sends out a pass or fail notification. If the server was too broken to run the script we would not get the pass notifications and other alerts would sound. If we get a fail notification, we know that we need to fix the backup site.
This is a pretty common challenge so I hope others can benefit from this simple solution.
Dec 31, 2012
A few people have been asking me about how my One Field Job Application experiment turned out (preliminary results here). We ended up hiring two excellent technical web PMs. Gerry Tamakloe works out of our Dublin Office. Gerry is a powerhouse: helping teams get the most out of our systems. He is not afraid to get into the details of an application and optimize it for an internal or external customer. Katie Methe works with me here in Massachusetts. In addition to managing projects, Katie handles deployments, QA, troubleshooting of our websites and GMO applications. I bombarded her with new stuff on her first day and she didn't even flinch.
In addition to finding some great people, this little experiment has reassured me that I am not unreasonable in expecting a web project manager to be capable of both managing people and doing technical tasks. A web project manager should rise to, rather than shrink away from, a technical challenge. Rather than just distributing work, A good web pm adds value to everything he/she touches: whether it be verifying and diagnosing a defect, deploying a fix, doing technical research, or configuring software.
Dec 20, 2012
For a long time, I have been advocating that marketing organizations build technology capabilities. Marketing I.T. and Enterprise I.T. have totally different mindsets. Marketing I.T. is more like product development with an emphasis on opportunity and innovation. Traditional I.T. prioritizes stability and cost control. Increasingly I have seen ownership of digital marketing technology moving from I.T. to marketing. Now I have a front row seat.
One of the unexpected aspects of my job here at Lionbridge is that I run Marketing I.T. In particular, I manage our hosting infrastructure and work with teams developing new sites and applications on it. Given that many marketing organizations are inheriting this responsibility, I figured I would share some of the tools/services that I have found useful. I am going to talk about a lot of different products here. I am not endorsed by any of these companies and I am only mentioning products that I like.
-
Hosting: Amazon Web Services (AWS) and Rackspace Cloud
We do everything in the cloud. We set up a multi-server infrastructure on AWS using Elastic Compute Cloud (EC2: virtual servers), the Elastic Load Balancing service (ELB), and Relational Database Service (RDS). Both ELB and RDS span multiple physical data centers which is good for availability. We have EC2 instances in multiple data centers too. Our sites are also replicated to infrastructure hosted on Rackspace Cloud so that if AWS has a major problem, we can re-route traffic over to Rackspace. We test our sites on Rackspace weekly. Both AWS and Rackspace are great. AWS has many more features but the tech support is very limited. You need to pay extra for support and it can take a while to get an answer. Rackspace support is amazing. If you don't have a decent sysadmin, I would go with Rackspace.
Ylastic makes administering AWS services much easier. The UI is not pretty but it is much better organized for doing specific tasks like managing backups and migrating and configuring servers. Ylastic also gives some insight into the health of the overall AWS infrastructure. The mobile UI is a big step up over the AWS management console on the little screen. We just use the basic level. At higher levels, you get some functionality to help manage your spend.
-
Monitoring and Alerting: ServerDensity, CloudWatch, and PagerDuty
AWS comes with its own monitoring service called CloudWatch. We have set up notifications to fire if the load balancer removes one of our servers because it isn't responding. We also wanted to have external monitoring services running so we could look at our RackSpace servers. Plus, it's a good idea to have your monitoring service independent from your hosting infrastructure in case your hosting infrastructure is too compromised to send an alert. We learned this the hard way when an AWS outage took out our monitoring as well. Most of our monitoring is done with a service called ServerDensity. This keeps track of internal server health metrics and we have it pinging the sites to make sure they are responding. Pingdom is also useful for checking if a site is up. We would use that if we didn't have ServerDensity
We do all of our alerting through a service called PagerDuty. While all monitoring services can send out pages and emails, the nice thing about PagerDuty is that you can set up on-call schedules and escalation pathways. This is important because I have a really small team and everyone has other jobs (which can require travel). Even a non-techie can be on the "site may be down" alert. Usually this is a false positive because one of the servers in the cluster bounced in and out of the load balancer. Whoever gets the notification checks the site and texts a resolution code back (resolve, acknowledge, or escalate). I have trained non-techies to update the DNS to send traffic to Rackspace in the case of an emergency.
-
Code Management: BitBucket
We have lots of different people building sites for us. Some are on staff, others are contractors or external agencies. We use BitBucket (with Git) for source code management. This allows me to easily bring in a contributor but thoroughly review his/her code before merging it into our code base. We follow the classic "Fork/Pull Request model". Some developers/agencies get it better than others. I am weeding out the folks who don't get it because it makes my life harder. I don't want to deal with zip files of directories and worry about coordinating the changes from different people. With a pull request, I can see every change and easily merge.
-
People
While all of this technology is great, it's the people that make it go. As I mentioned earlier, my team is small. We get a lot of design and development help from outside contractors and agencies. I share sysadmin work with a really good contractor that knows much more than I do about managing servers. Having a "virtual team" is nice for scalability but it sometimes presents challenges for scheduling. I found a web project manager (with the help of my one field job application) who can handle a lot of basic tech tasks like running deployments and migrating sites. She has SSH access to all of our servers and can do things like restart Apache. She only started a couple of weeks ago and she is already making a huge contribution.
-
Process
We track all of our work in a ticket tracking tool called DOT (which we also use for our GMO clients). We also use DOT for tracking time so we can see how much effort we spend on various development projects. We group infrastructure projects into milestones that represent maintenance windows. Leading up to a maintenance window, we prepare the fixes and test them on a QA environment. We defer tickets that we are not confident that we can complete. Once the milestone is locked down, we send out an email to stakeholders explaining what we are doing, when we are doing it, and how it could possibly affect them. Then, after we complete the maintenance window, we send out a completed email, reminding of any relevant changes.
Overall, I am impressed with what a small team can do on a limited budget. By using cloud-based technologies, we can afford levels of redundancy and sophistication that would be prohibitively expensive to buy up-front: multiple data centers, generators, alerting systems, source code management… People-wise, we probably have around .5 FTE spread across several people (internal and external) managing and extending this infrastructure. These people have other responsibilities such as building and managing our services and products.
The best part of this whole arrangement is that we can be ultra-responsive. If something is important to a marketing initiative, we can act on it immediately. Our work does not go into a larger queue, where it may be misassigned or assigned to someone who doesn't have the complete context to do the work properly. The social dynamic is different as well. We are part of the team. Our motivations are aligned and we don't have those defensive postures that I.T. needs to fend off the entire organization. When we push back, we do so as peers and can explain why in terms that our peers can relate to. I think all mid to large sized organizations need a marketing I.T. team and this seems like a good way to structure it.
Dec 17, 2012
Warning: geeky coding post
One of my responsibilities at Lionbridge is running infrastructure for our many marketing sites and applications. Like all good technical organizations, our development and deployment processes revolve around a source code management (SCM) system (in our case Git). Because we are running on a CMS (Wordpress - hold the religious war on whether Wordpress is a CMS), our websites are a combination of platform (Wordpress), customization (plugins and themes), configuration, and content. The question is: how much of this do you put into your SCM? Let's start with the obvious. You don't put content in your SCM. With configuration, it depends. Some frameworks allow you to tier your configuration options between global and environment-specific. For example, this is how I handle Django settings. I haven't come up with a clever way to do this in Wordpress so, for now, I am keeping wp-config.php out of the SCM.
As for platform and customizations, my tendency has always been to keep the platform out of the SCM. In this model, your build process is to install the platform than then deploy the themes and plugins from source control. I have done many projects in this way and it worked quite well. But another developer set up our Wordpress infrastructure for these sites and his preference was to put the whole Wordpress install into SCM and do a "git pull" to update the whole site. I also didn't love the idea of using Git to deploy. I like to pull the code to some alternative machine (my workstation or a server), (compile/)package it, and then push it to the web farm. Fabric is an excellent tool for this. You can still use Fabric in this scenario to execute Git commands on the remote servers but it still doesn't feel right to me. I prefer that runtime servers have as little software running on them as possible.
At first I hated this set up. I missed a developer being able to install our themes and plugins into any old Wordpress instance. I had doubts about the complexity of administration settings and the potential of editing source-controlled files trough the web. But I kept an open mind and I have come around. Here are the reasons:
-
The upgrade process is a lot tighter. Now I just upgrade Wordpress on a development instance, test, and then deploy the upgrade through the normal code deployment process. Plugins are handled the same way.
-
Customization compatibility issues just go away. When we have an outside contractor work around the system by working in his/her own Wordpress we run into issues where the new code is incompatible with versions of Wordpress and our installed plugins. This simply doesn't happen when you check out the whole platform.
-
Your SCM provides diff'ing functionality. Suspect that one of your environments does not conform to the rest? Worried that you have been hacked? Simply do a "git status" and see what files are different from the repository.
One thing to keep in mind: in this model you don't do any upgrades or plugin installation through the web. You also need to turn off the ability to edit theme and plugin code through the web. We needed to do this anyway because we have a clustered infrastructure and those changes need to be propagated across every web server in the farm.
It took me a really long time to come around to liking this setup. I think a big part of that is my Java background. Java makes a big deal about packaging and deployment. Pulling directly from Git seems more common in the PHP world, which never had a build process. But now, I am pretty happy with this setup. The best part is ensuring against compatibility issues (#2 on my list above). I still prefer deploying code to servers rather than pulling code from them but my conviction is steadily eroding. It's kind of nice not needing scripts to move around files and avoid overwriting files that are managed independently on each environment.
Just out of curiosity, I would love to know what source code management and deployment processes other PHP developer use. Let me know.