Jun 28, 2010
Most new site CMS implementations (as opposed to site migrations from one CMS to another) start off with a set of HTML mockups. This can be a convenient starting place because, in addition to showing how the pages should look and informing the content model, having the HTML gives a good head start to presentation template development. Ideally the template developer just has to replace the sample "Lorem Ipsum" text with a tagging syntax that retrieves real content from the repository. There are even some graphical tools that help a developer map regions on the mockup with content from the repository. However, often moving from HTML mockups to presentation templates isn't so smooth. Sometimes the HTML has to be re-written from the ground up.
The most common source of problems is when the HTML is too specific. This usually occurs when the designer/developer who produces the mockups is accustomed building static HTML websites where she has full control over everything. HTML and CSS for an CMS implementation has to account for the fact that control is shared between the template and the content contributor. While the template controls the overall layout, the control contributor controls the navigation, text, images, and (with the help of a rich text editor) can even style body content. HTML code that is rigid and brittle breaks when stretched by unanticipated content. Here are some things to look out for.
-
Hard coded height and width dimensions on image tags. Most content contributors don't know the first thing about aspect ratios. They upload a picture and don't understand why it is squished on the page. While most CMS these can automatically scale images (and even if they can't the browser will), they can't all reshape them. While some CMS support cropping functionality for thumbnails, few content contributors know how to use it to precisely shape an image. I usually recommend setting only one dimension (usually width) and then letting the other dimension (usually the height) do what it needs to do. If you really need to control both, you can use this little background image trick:
<div class="picture" style="background: url(<<horizontally scaled image path>>) no-repeat; height:150px;"></div>
This uses the image CMS's image scaling to set the width and vertically crops the image after 150 pixels by making it a background image.
-
Overusing element ids. When you are only building a few pages and you want very direct control over elements, there is a temptation to code CSS to reference specific element ids rather than classes. In some cases, this makes sense. For example, when there is only one global left navigation component. However, it makes less sense for anything that a content contributor might have control over — like items in that navigational menu or anything else that repeats. I haven't used DreamWeaver (DreadWeaver, as I like to say) in years but I suspect that the HTML/CSS auto-generation generation prefers using IDs over classes because that is where I see it the most. The worst case I have seen was a sample search result page with every search result individually styled with element ids.
-
Over-complicated HTML. HTML is only going to get more complicated when it is infused with template syntax. It is best to start with HTML code that is as simple and terse as it can be. If a designer is still using nested tables to position things, have him work in photoshop. The more styling you can do in CSS the better. This will make templates cleaner, more efficient, and easier to manage. Plus, your CSS will survive a migration to another CMS better than your template code will.
-
Using images rather than text headings. While the font control afforded by images is nice, avoid using images for anything dealing with the navigation or page names. Otherwise content contributors will not be able to create new pages or re-organize the navigation without a designer to produce images. If you have a top level navigation that is unlikely to change, you can compromise by building images just for the top level page names. A decent strategy is to code the HTML like
<h1 class="section-heading <<dynamic section name in lowercase >>"><<sectionname>></h1>
for example:
<h1 class="section-heading about">About</h1>
This way, if a content contributor introduces a new section that doesn't have an image or style yet, there is a decent fallback of styled text.
-
Too many layouts. Most web content management systems prefer you to have an overall page layout template (also known as a master page) that is used for nearly all of the pages of the site and then content-type-specific templates that render in the "content area" in the center of the page. Things like the header, footer and global navigation components go in the page layout template. In many systems these two templates are not very much aware of each other because they are rendered at different times within the page generation process. The trick is to determine what portions of the page to put in the global template and what to put in the content-type specific templates. The more you put in the content-specific templates, the more flexibility you have but you also wind up having redundant code that adds management overhead. You also want to make sure that the design does not specify too many options for content presentation templates. In addition to adding to maintenance overhead, this also confuses the user. When lots of variability is required, it is a good technique to design the implementation to allow contributors to build pages with blocks of content. This way, the presentation template just has to define "slots" that contributors can fill (or not fill) with content.
Most of these tips will come more naturally to an advanced HTML that really knows his stuff than a pure designer with design tools that can create HTML. However, even the best HTML developers can have mental lapses when they get into a production groove. It is a good idea to understand the HTML producer's skill-set before assigning the task of HTML production and set expectations. Otherwise, you will probably get a rude awakening when template development is scheduled to start. If this type of HTML production is new to your team and you would like them to learn it, account for this learning by holding frequent reviews of the HTML code as it being produced. Start with the most simple content type (like a generic page) so you can focus on the global page layout and get alignment on static vs. variable components. Over time, your team will instinctively notice HTML code that works for the mockup but will be problematic in a presentation template.
Jun 24, 2010
Whenever Amazon announces news about it's Kindle product, like with the recent Kindle price drop, I find myself referring to my reasons for not buying a Kindle. So far they are working out pretty well for me. The strongest argument has been the inability to share (first on the list). When I buy a physical book, which is usually not much more expensive than the digital version, I don't just buy the ability read the book myself. I am also buying something that I can share with others. Frequently I mention a book to someone and grab my copy to lend. And roughly half of the books that I read are on loan from others. You don't get this experience from a digital book and I would miss it.
Personally, I would reconsider my decision not to buy a Kindle if it had a "lend" feature. Here is how it would work. If I owned a digital copy of a book, I could click a "lend" button that would bring up a list of my friends. I would be able to set the length of the loan. During that period, the lendee would have access to the book but I would not. As the owner of the book, I could retrieve the book and, in doing so, remove it from the lendee's library. This feature could also be enabled for public and academic libraries.
This move would be great for Amazon (or a competitor that did it first). It would encourage people to buy the reader device when their friends buy one. It makes the reader more valuable and viral. It would alleviate feature/function competition. You would buy the reader your friends have, not the flashiest product with the best C|Net review. Publisher's would probably not be so keen on the idea. They would see fewer eBook sales. I think this issue could be addressed by Amazon increasing the digital copy price and sharing more revenue with the publisher. For reference books and classics, the publisher could see sales to people who borrowed the book but wanted their own copy.
This reminds me of Kevin Kelly's classic post "Better than Free," where he lists characteristics of content that make it worth paying for. One of the characteristics is "Embodiment," which digital content lacks. Making a digital edition virtually transferable (and not copyable) would certainly add embodiment because it would make it behave more like a physical asset.
Amazon (or any other digital reader maker): please steal this idea (if you haven't already thought of it yourself). I would really like to see lending digital content happen.
Jun 11, 2010
Ever since I got into web content management, I have advised my clients to avoid the word "user." It's a useless word because you are never quite sure if someone is talking about a user of the CMS, or a user of the website. For this reason, I get my clients to adopt the words "contributor" and "visitor." A contributor is a person that contributes content or participates in the content workflow of the content management system. A visitor consumes content on the website.
The primary goal of a content management system is to mediate between these two populations. If a CMS was only to think of the contributor, the content would be poorly structured, cluttered, chaotically structured, and hard to find. By the way, pretty much every organization has one of those systems — it's called a shared drive. If a CMS only represented the visitors (or other consumers of content such as other systems), it would insist on extremely fine-grain structure for maximum reuse, pristine HTML (sorry, no WYSIWYG editors), and perfect quality (hello 10 step workflows). The CMS applies structure and rules to establish a compromise between these two groups.
Web 2.0-style sites jumble this model up a bit because the line between contributor and visitor are blurring. Visitors can potentially contribute. Web content management systems like Drupal, Plone and many others merge the contributor interface into the externally facing website. These platforms tend to call registered users (contributors and visitors) "members" and, by default, allow members registered themselves. The distinction between a self registered member and a "SuperUser" is just a matter of permissions.
I still think that the distinction of contributor and visitor is useful because members need to wear different hats. Sometimes they are visitors on the site simply trying find something. Other times they are contributors wanting to post something. The CMS is still mediating but instead of mediating between different types of users, it is potentially mediating between the same user in different contexts. It forces the contributor to put in a little extra effort to make life easier when he becomes a visitor. It would be a little like Clippy telling you "Oh, you don't want to use that file name and place that document there because you will NEVER find it again! And while you are at it, maybe you should print that out because you messed with the margins and I bet its going to look like hell." Clippy doesn't do that and we still find him annoying. Now you wonder why nobody loves their content management system?
Jun 09, 2010
Jeff Cram started blog series called post launch paradigm with a great post called "Your website is not a project." The article lists all the ways companies fail when they think of a website as a project to be completed.
If a website is not a project, what is it? Jeff calls it an "ongoing process." I call it a "product." Website product management is becoming an increasingly important service offering for Content Here and it is a natural extension of the selection work that I have been doing over the first three years of the company. During a selection engagement I create a road map of functionality to be implemented over time and set expectations for user adoption and incremental improvement. Recently selection clients have been engaging Content Here after implementation to help them progress along that road map. This feels great on a number of levels: these clients realize that their websites are not projects, they have bought in to the concept of continuous improvement, and I get to see the clients working with the products that they have selected. I even get to go through code once in a while!
May 11, 2010
I am currently providing web product management services for two clients. One client is a start-up launching a new web-based product. The other is a 100 year old newspaper. While at face value these two clients couldn't appear to be more different, they are actually quite similar. Both are trying to innovate a viable product. The startup is building a new concept. The newspaper is a trying to re-imagine an old concept. In both cases the development backlog is a chaotic mess of items that range from little tweaks to major features. There is impatience for progress; but that urgency needs to be balanced with the need to build something that is scalable and sustainable if the business succeeds. The truth is most websites operate under these conditions to some degree. It is just the ambition of these two businesses raises the stakes and the stress level.
To be successful in these projects, I have had to draw on lots of different skills and experiences. Many of the concepts and techniques come from agile methodologies like Scrum and Lean software development. What follows is a list of principles and practices that I have found to be effective.
-
Establish a regular (2-3 week) release cycle. Everyone benefits from a regular release cycle. Stakeholders get the satisfaction of seeing progress. They don't panic if one of their requests doesn't get into the current release if there is a chance that it will be addressed in a subsequent release. The sooner a new feature hits the production site, the sooner it can be measured and improved. Shorter development cycles also mean smaller releases that are easier to test. Site visitors perceive a constantly improving site as being vibrant.
-
Define and communicate prioritization criteria. In order to keep releases small, you need a clear and open scoping process. Enhancement requests need to be evaluated against the site goals (such as creating new revenue opportunities, cutting costs, maintaining credibility, etc.). Without this kind of guidance, development gets chaotic. Developer time is not concentrated on work that matters. The pipeline tends to get clogged with small tweaks; larger, more substantial improvements never get done.
-
Make each release a blend of stakeholder-focused improvements and code maintenance. When code is not regularly optimized and refactored, entropy takes over and it becomes less maintainable. Development teams that are exclusively driven by stakeholder requests don't have time to keep the codebase clean. A broken window effect causes messy code to beget messy code. For this reason every release milestone should contain a balance of improvements that stakeholders see (new functionality, presentation template changes, etc.) and maintenance tasks (refactoring code, improving management scripts and infrastructure, etc.). By maintaining this discipline, the quality of the application improves (rather than degrades) over time.
-
Don't forget the HotFix queue. Even though you might have a methodical development plan, emergencies happen. In addition to regularly spaced released milestones, I typically create a "HotFix" milestone with a rolling due date of "yesterday." Emergency requests go into the HotFix queue and get addressed and deployed immediately. Of course, only I can put things into the HotFix queue and I base that decision on very specific criteria: current functionality is compromised, inaction is costing money (or some other measure of value like reputation), and it is a quick fix.
-
Write good tickets. Every change request gets entered in a ticket tracking system. Bug requests should be extremely descriptive: URLs, screenshots, steps to reproduce. Feature requests take the form of a full specification complete with annotated wireframes or mockups. Every new element shown needs an annotation describing the source of information and behavior. It is also a good idea to put in test conditions so that the QA staff know how to verify it is working.
-
Use your source code control system effectively. Create tags to remember milestones in the development history. Use branches only when you are simultaneously working on two versions of the application. The most likely reasons for branching are:
Don't use branches for personal work areas or to manage environment-specific configurations. Merging will be a pain and it will delay any integration testing you will need to do.
-
Automate deployments. Deployments should be simple and mindless. There should be one step to push the same exact code that was tested on the QA environment to the production environments. If someone needs to manually copy individual files, you are doing it wrong. At a previous client (a very large magazine publisher), we used AnthillPro for continuous integration and deployments. Each build of the application was stored in an build artifact library where it could be deployed to different environments with a push of a button. There were cool reports that showed you want build number was deployed where. But that was for managing 50+ applications across hundreds of servers. Now I am using lighter weight tools like Fabric to script builds and deployments.
-
Build a talented and committed team. I strongly believe that there is no room for mediocrity on an agile development team. Working in this way requires a lot of trust. Stakeholders need to trust that developers are working efficiently and doing necessary things. Developers need to rely on each other to communicate and make good decisions. You don't get that trust unless developers know the technology and are passionate about their craft.
If the website or web application that you manage is your product (or is critical to deliver your product), you need to manage it with this level of discipline and rigor. Otherwise the site will stagnate and you will be unprepared to respond to new market challenges and opportunities.
May 04, 2010
By now most industry analysts have grown skeptical of Oracle's commitment to web content management (WCM). Those analysts that are still in denial are either too focused on the document management side of enterprise content management (ECM) to even care or they are on Oracle's payroll. The writing has been on the wall for a while now. Before Oracle bought it, Stellent had (in my opinion) the best WCM functionality of any of the document-oriented ECM products. They were miles ahead of EMC/Documentum and IBM/FileNet. Stellent was even edging past traditional WCM products like Vignette and Interwoven who were neglecting WCM to concentrate on their ECM offering. The Stellent acquisition happened right before the release of a new version that introduced big WCM improvements. After the acquisition, Stellent got dumped into the "Fusion Middleware" (AKA "Neither Database nor ERP") division which was a clear sign that Oracle didn't want to spend too much time understanding what it bought.
The reason why Oracle bought Stellent is pretty clear. For readers who are not CMS historians, many years ago Stellent bought a company called "Inso" which developed the filters that could convert documents into different formats. Microsoft has Inso to thank for breaking WordPerfect's and Lotus 123's holds on their respective markets. Because of OEM'ed Inso technology, an MS Word user could open a WordPerfect document. Stellent used the acquired Inso technology to lead the market in word-processing-to-web functionality. More than with any other ECM product, a Stellent UCM user could realistically use MS Word to maintain a structured web asset. Oracle's plan for Stellent was to use those filters to help its document repository story. At the time, Oracle was pitching its "ECM-light" vision that positioned its database as a step up from a file system for storing documents. The database could store metadata and provided a search interface that could list documents in different ways. Inso filters helped parse documents for better indexing and also introduced a capability for exporting into different formats. Plus the Stellent user interface was a big improvement over anything that Oracle could cook up (no, knowledge workers do not want to work in SQLPlus).
Wow, that was some rant. But why I am talking about that now? Well, I was just listening to an NPR Environment podcast that was underwritten by Oracle (thanks Oracle, BTW). When reading the Oracle underwriter statement, the presenter instructed listeners to "visit www.oracle.com/ironman2 to learn more." Now we all know that Oracle is a big company and are probably too busy to create marketing landing pages for all of their different advertising campaigns (no matter how easy it is to do). You can make the old "cobbler's son" excuse. But in this era where the premium WCM vendors are selling on "interactive marketing" and "engagement" functionality wouldn't you think that Oracle would make an effort? Wouldn't it be helpful to know whether traffic was coming from an NPR or Iron Man 2 advertising spot? Ironically, I seem to remember A/B testing, marketing landing pages, and reporting functionality were all part of that mid-acquisition Stellent version. Apparently the Oracle marketing team seems not to have discovered it.
Apr 30, 2010
My friend and former Optaros colleague Jeff Potts recently announced that he has left Optaros to form a new company called Metaversant. Jeff was Optaros' superstar Alfresco guy. He put Optaros on the Alfresco map and contributed to the Alfresco community by writing a great book (The Alfresco Developer Guide), maintaining useful information on his blog, and also publicly pushing Alfresco in the right direction. Jeff is a charter member of my informal "Content Here Information Partner (CHIPs)" network and I have regular briefings with him to keep up to date on all things Alfresco.
Since Optaros has shifted its strategy to focus on the intersection of community, commerce, and content, Alfresco's position as a core offering has diminished. Alfresco is more oriented toward file-based collaboration, intranets, and digital asset management than social publishing and commerce. Metaversant will focus on training and advising Alfresco customers. I admire Jeff's expertise in and passion and I know that he will be successful in this new venture. He will certainly get referrals from me.
Apr 26, 2010
There has been a lot of Twitter chatter about this New York Times article on offshore captcha circumvention. The article describes how link spammers are hiring cheap offshore labor to manually solve captchas and dump comment spam on websites. If you use captcha as the only way to prevent comment spam, you should worry. However, if you are like me and use captcha only to level the playing field (by taking robots out of the equation), this is not a problem. In fact, I am happy that it raises the cost of link spamming and safe jobs are going to people that need them.
If you are manual link spammer, don't accept less than a penny a comment. You deserve it!
Apr 26, 2010
Mark your calendars, World Plone Day is on April 28th. World Plone Day is a free, annual, international event designed to introduce the Plone content management system to people outside of the Plone community. This year it is being held in 36 locations in 29 countries. The agenda usually contains a balance of business and technical topics. I just had a look at the Boston World Plone Day agenda and it looks particularly good.
If you have not looked at Plone recently, you should. With the official release of version 4.0 right around the corner, a lot of changes have happened. The architecture leverages more of the new Zope 3 technologies, performance has improved, and development techniques have evolved. A considerable amount of work is being done to make theming easier using tools like Deliverance. Also, the NoSQL movement hype may make the underlying object database (ZODB) less intimidating to architects. From a user perspective, the team has focused on some subtle improvements such as switching the default rich text editor to TinyMCE and creating a new default theme.
Apr 14, 2010
Over the past few days, I have been involved in a number of conversations about supporting Internet Explorer 6. Arguing about when to drop support for outdated browsers is a sport that is as old as the web itself. There is nothing really new here but the IE6 support debate feels particularly emotional — not as charged as back when people were arguing for only supporting Internet Explorer, but close.
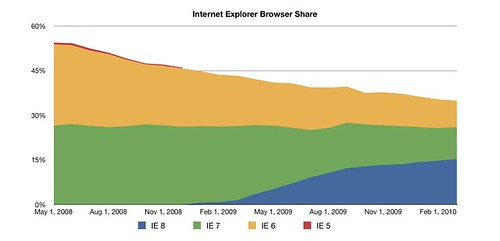
IE6 had a really long run. It was Microsoft's browser offering for 5 years (late 2001 through late 2006). Up to that point, Microsoft was releasing a major version of IE every year. Now it looks like they are settling into a pace of every other year. That means that IE 6 was installed on a lot of computers. In particular, a lot of computers that were bought when internet usage was starting to get really ubiquitous. In many businesses and households, these computers were bought as an internet appliance with a really long expected lifespan — like a refrigerator or a telephone. Companies are hanging onto their old IE6 computers. Vista's flop means that Windows XP is still the corporate standard and IE6 comes with XP. Unless you have a technical or information-intensive job or are working at a new company, chances are you are on a highly locked down, old Windows XP computer that your employer begrudgingly bought to give you access to email and the intranet. Your employer doesn't want to upgrade your machine unless absolutely necessary. That usage pattern has caused IE6 to linger longer than other browsers. See how IE8 seems to eat up more of IE7's market share than IE6's?
Not only do the numbers of IE6 user continue to be significant, the types of users seem to be desirable as well: internet n00bs that click on ads and buy what they see (with the money that was not taken by Nigerian 419 scams).
Technical people have little empathy for these types of users. The first thing we do when we boot up a relative's computer for home tech support is stop the malware/adware processes, install Firefox, and hide the IE icon. As developers, we know that a requirement for IE6 support translates into maintaining two code bases: one that uses all the goodness of the latest HTML and CSS standards and fast Javascript engines; and another that is a bundle of hacks to compensate for IE6's quirks. Many web development firms I know are starting to charge an additional 20% - 30% to include IE6 support. They are not price gauging. This is probably less than the actual cost. The customer will probably invest an even larger percentage of additional resources to maintain the application.
For this reason, an increasingly larger number of websites are discontinuing support for IE6. They have done the calculations and have decided that the convenience for the IE6 hold-outs is not worth additional cost and drag on innovation. I don't mean to sound like a jerk, but big web properties (like Google, Microsoft, and Content Here) dropping IE6 is a good thing for everyone (almost):
- Visitors will have a greater incentive to upgrade. If they can't upgrade on their own, they can make the case to their employers that running a 9 year old browser is not acceptable.
- The more modern technology will increase overall security
- Web sites and applications can be developed more cheaply and with higher quality.
- The spending to upgrade outdated equipment will be good for the economy. Companies and households don't have to buy $2,000 laptops, they can probably get away with cheap NetBooks.
This site never supported IE6. If you are stuck on that browser, I am sorry for the inconvenience that I have caused. But, I figure you are used to browsing broken websites by now :)